|
电信基础局端、视频基础局端以及影像应用等对于带宽的要求迅速提升。这些系统需要支持具有更高分辨率、更快帧速率以及更出色音质的视频流。同时,上述系统还要提高通道密度,降低每通道的功耗。此外,该市场不仅要求提高外设与存储器的集成度,而且还要进一步缩减电路板面积,从而节约系统成本。开发人员需要高度可扩展的灵活硅芯片器件和工具来帮助他们跟上市场发展趋势的要求。
用于数字信号处理器 (DSP) 的一些传统高性能 I/O 在可靠性、带宽充足性以及可扩展性等方面都存在一定的局限性。Serial RapidIO (sRIO) 能够通过提供一种高性能的分组交换式互连技术解决这种局限性问题,这对复杂的 DSP 拓扑而言非常有用。与其前代技术不同,sRIO 不需要与存储器共享接口,而且既能作为主系统、又能作为从系统运行。此外,其还可支持较长的物理连接距离以及硬件级故障检测/纠错、状态/确认反馈以及带内中断/信号发送等。
德州仪器 (TI) 推出的 TMS320C6455 DSP 等高级 DSP 现已集成了 sRIO 接口。这种接口具有极高的效率,能直接连接至 DSP 的 DMA 引擎,通过事务处理代理寄存器来降低控制开销。为了提高 DMA 系统数据处理的效率,可对数据设定优先级,而且该接口还支持多个事务处理的排队。
复杂系统拓扑中的 sRIO
首先,我们必须了解 sRIO 在复杂系统拓扑中发挥的作用,明确它在物理系统的实施过程中如何提高灵活性。sRIO 可支持芯片之间以板间通信,速度高达 20 Gb/s 乃至更高。sRIO 提供 1X 和 4X 宽度的 1.25、2.5 或 3.125 GHz 双向链接,每向吞吐速率高达 10 Gb/s。
利用 sRIO,设计人员能够确定如何实现多个器件的最佳连接。DSP 可直接进行网形、环形以及星形拓扑的连接,也可通过交换机进行多个 DSP 的连接,彼此之间有无本地连接均可。此外,我们还可采用 sRIO 一并连接 DSP、FPGA 和 ASIC。这种高度的灵活性使设计人员能根据应用数据流的需要任意安排组件,而不会因为接口或协议的限制影响系统设计。
举例来说,一个简单的系统可以具备两个通过 4 倍速链接相连的 DSP。另一个系统则要求更高的计算能力,不过不需要更多 I/O。这种系统可以由 5 个 DSP 组成,每个 DSP 都直接通过 1 倍速链接彼此相连。第三个系统也包含 5 个 DSP,它们均采用 4 倍速链接连接至中央交换机,以实现更佳的 I/O 性能(图 1)。第四个系统则有更繁重的计算要求,其中可能包含 12 个乃至更多的 DSP,它们均通过 4 倍速链接连接至一个或多个交换机的系统架构,从而实现最高的计算能力和 I/O 带宽。

图 1. 在本例中,sRIO 能灵活地连接所有五个 DSP
支持 sRIO 的系统能够通过充分利用上述特性显著提高整体性能。例如,在无线基础设施系统中,总共三到六个速度达 Gbits/s 的天线数据通常由可处理 24 到 48 个天线流 (antenna stream) 的 ASIC 或 FPGA 支持,这时每个基站的速率约为 123 Mbits/s。另一方面,用户数据通常在 DSP 上处理,每个用户通道速度约 19 Mbits/s,统一采用共享的 EMIF 通道。采用链接 sRIO 通道的 DSP 使用户数据和天线数据能独立得到处理。采用 DSP 所需的成本不仅大大低于 FPGA 或 ASIC,而且在 24 到 48 个天线流的系统中能处理相同的数据速率,每个通道速度约为 123 Mbits/s,因此天线数据速度总共能到每秒 3 到 6 Gbits。对于用户数据而言,诸如最新 DSP 系列的较高核心速度、较快的 sRIO I/O 速度,以及能释放外部存储器带宽等优异特性,使通道密度能够提高到每 DSP 达 128 个用户通道,每通道速度为 19 Mbits/s,这样整体而言每个 DSP 的用户数据总速度达 2.5 Gbits/s。
消息传递
软件开发人员不仅能够受益于 sRIO 接口具有的更高性能和更高灵活性,而且他们无论采用低级编程技术还是高级编程技术均可进行应用开发。如果使用低级直接 I/O 方案,编程人员必须指定目标和地址,这种方案在能够实现最佳性能的同时,还非常适用于在设计时就已知目标缓冲方案的应用,并且应用的分组是固定的。但是,这种方法的缺点是开发人员必须了解远程处理器的物理存储器映射,这使第三方集成非常困难。
高级消息传递方案能够在无需进行大量低级器件编程的情况下就能提供一种更抽象的通信方法。这种方法对目标缓冲方案未知的应用最为适用,而且对于应用分组未知或者比较灵活的情况也很适用。此外,消息传递接口能够显著缩短用于增加或减少应用处理器所需的时间。
数家嵌入式处理器厂商为 sRIO 提供内核级软件层支持。例如,在 TI DSP 中,消息传递由 DSP/BIOSTM 软件内核基础 Message Queue (MSGQ) 模块提供支持,这使应用开发人员能在更高级别的抽象水平上设计软件应用。
消息传递使应用能够通过 sRIO 互连更高效地与其它 DSP 通信。通过这种方法发送的消息,其优先级高于数据缓冲,这一点非常有用,因为以更高的优先级控制数据通常来说是更好的做法。MSGQ 能在无需修改源代码的情况下在处理器中移动读取器和写入器,因此我们能在单个处理器上进行开发,而且能方便地针对多处理器系统进行缩放。也就是说,写入器不用了解读取器驻留在哪个处理器上,这不仅能简化集成,而且还能简化客户端/服务器应用等的开发工作。
此外,MSGQ 还可支持消息的零拷贝传输,假定底层物理介质支持处理器间零拷贝。零拷贝基本说来就是指针传递 (pointer passing),而不是将消息内容拷贝到其它消息中。我们可在单个的处理器上完成上述操作,也可在共享存储器的多部处理器完成。由于能从特定集 (specific pool) 分配消息,因而我们能轻松地实现服务质量 (QoS) 特性,如针对关键资源提高性能、加快速度等。
MSGQ 模块
MSGQ 模块包括 API 接口、分配器以及传输机制等(图 2)。API 接口将应用与传输机制和分配器相隔离。分配器为消息分配提供接口,而传输机制则为处理器间的消息传输提供接口。
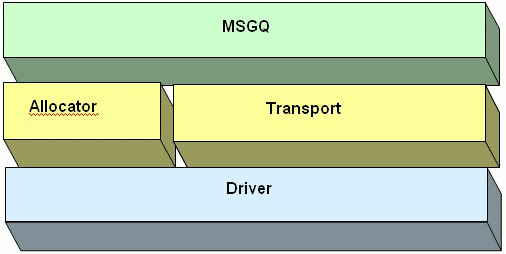
图 2. MSGQ 模块
必须首先对在 MSGQ 模块中发送的所有消息进行分配。我们能用多个分配器从一个集分配关键信息,再从另一个集分配非关键信息。我们可以举一个简单的分配器的实例,即所谓STATICPOOL 的静态分配机制,其负责管理由应用提供的静态缓冲器。在初始化阶段,STATICPOOL 分配器会接收地址、缓冲器长度以及请求消息的大小。可将缓冲器分为指定的消息大小块,并放置在链接列表中,这有助于简化消息定位。
接下来,传输机制在物理链接上将消息发送给另一处理器上的目标消息队列 (destination message queue)(图 3)。通过传输接口,应用能在不改变自身的情况下改变底层通信机制,不过需要配置传输机制。这种方案将物理链接的具体技术问题隐藏起来,提高了应用的可移植性。
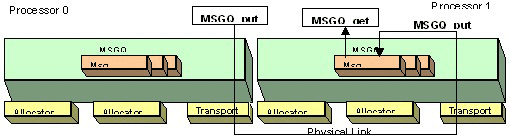
图 3:传输功能
消息队列具有整个系统内唯一的名称,发送器能通过其名称来定位消息队列。所有通过 MSGQ 模块发送的消息都必须在第一字段编码 MSGQ_MsgHeader,之所以必须是因为内部指令就保存在报头中。报头由传输机制和 MSGQ 模块内部使用。消息发送到不同的处理器时,传输机制对消息报头部分的任何字大小和字节库 (endian) 差异进行处理。应用负责消息专用部分所需的转换。
由于不同的处理器可能采用不同的调用模块(系统中的消息队列),因此 MSGQ 模块允许应用写入器指定通知机制的类型,这非常有用,因为用户能指定通知机制,并相应地调节 MSGQ。不过,一旦将消息发送给读取器,写入器就会丢掉消息的拥有权,并且不能再修改或释放消息,因此在发送之前确保消息的正确性至关重要。当读取器接收消息后,必须释放消息或重复使用消息。
消息队列的定位
MSGQ 为每个打开的消息队列保留一个消息存储库。消息队列的读取器从消息队列的存储库中获取消息。如果需要将读取器或写入器线程移至另一个处理器,就无需更改读取器或写入器代码。
定位消息队列有两种办法:同步定位和异步定位。采用同步定位法情况下(可能采取阻塞方法),消息管理每个传输机制的查询,以查找所需消息队列的位置。采用异步定位法情况下,将消息队列定位后会发送异步定位消息给指定的消息队列。
同步法的实施更为简便,但要求用于阻塞队列的一些参数,如定位线程等。虽然异步法无需进行阻塞,但实际操作更为困难,难以使用。
我们可通过应用指定的通知机制来支持同步或异步操作。用户可指定通知机制,如信号量和中断记入等,这样就不用再遵循特定的调用模式。消息发送器能嵌入消息队列,消息读取器则能提取消息队列并做出回答。
数据流示例
以下我们给出来自某个应用的基本数据流程,根据设计,该应用可在两个 DSP 之间移动数据。在本例中,我们用多个集来管理不同类型的消息,其中包括应用、传输内部控制消息以及错误消息等。采用不同的集并不是必需的,但这样做有助于简化应用的维护。举例来说,管理若干个小集有时要比管理单个大集要简单。此外,如果消息大小有所不同,那么采用单个大集的话就会浪费大量存储器空间,因为这时必须支持最差情况下的空间要求。
本例中的流程可运行在 TI 的 TMS320C6455 EVM 等评估板 (EVM) 上,这款评估板采用两个通过 sRIO 实现互连的 1GHz TMS320C6455 DSP。该评估板提供了完整的代码以供参考:
main()
if processor 0: 打开雇主消息队列并
创建雇主线程。
if processor 1: 打开雇员消息队列并
创建雇员线程。
打开错误消息队列并创建错误线程。
srio_init to initialize peripheral
workerThread()
Loop
MSGQ_get message from the worker queue
确定发送器
向发送器发送特定数量的消息
bossThread()
MSGQ_locate to locate worker queue
Loop
MSGQ_alloc message
使用要接收的多个消息来填充消息。
MSGQ_setSrcQueue to embedded boss’s message queue
MSGQ_put message to reader
Loop
MSGQ_get message from the boss queue
errorThread()
Loop
MSGQ_get message from the error queue
Log MQT error via LOG_printf
在单个处理器上发送消息
下面将介绍在单个处理器上发送和接收消息的幕后情况,这个过程分为任务一和任务二。任务二由操作系统 (OS) 进行调用,打开 MSGQ 队列,并为该消息队列指定 pend 与 post函数。如果没有消息,则使用 pend 函数,在而向消息队列发送消息时则调用 post 函数。
如果 MSGQ 模块获得了没有待决消息的信息,那么就可运行任务一,但必须读取队列标识符,并定位适当的队列,以免其位于不同的处理器上。通常在启动时定位队列对性能几乎没有什么影响。此外,任务一在向任务二发送消息之前还必须为消息传输分配存储器。
一旦任务一发送消息,就不能再对消息进行处理,因为这时 MSGQ 已拥有该消息,MSGQ 会将该消息分配给适当的队列。任务二获得了有消息的信息,并准备接收消息。一旦任务二获得消息,就能够对消息进行重复使用,并将其发送回任务一。例如,如果两个任务要将消息来回传输,那么就仅需分配开始的消息。若读取器接收到消息,就能相应地更新内容,然后将其发回。这样,任务二就能够处理消息,一旦处理完成,消息就返回到存储器管理,任务二也就不能再对该消息进行处理。消息传输至此完成。
消息传递可通过为数据移动提供虚拟接口来显著简化复杂处理器通信的开发与维护。
|